
It’s finale time.
The final part of the Level Up: Event-Driven Architecture article series is here!
In the previous four parts, we:
- Defined the nature of messages to expect in queues, event buses, and streams.
- Covered queues.
- Covered pub/sub (inc. event buses)
- Covered streams.
Today we tackle some problems and establish some patterns you can take home with you.
Where Most Problems Stem From
When engineering teams are doing event-driven architecture wrong, it normally stems from the incorrect use of command and event messaging. Perhaps they are firing commands at event buses, or maybe they are streaming complete state events rather than state delta.
The decision tree below is a generalized flow I like to use when deciding how to tackle a technical problem. It is not a one-size-fits-all silver bullet - but it helps.
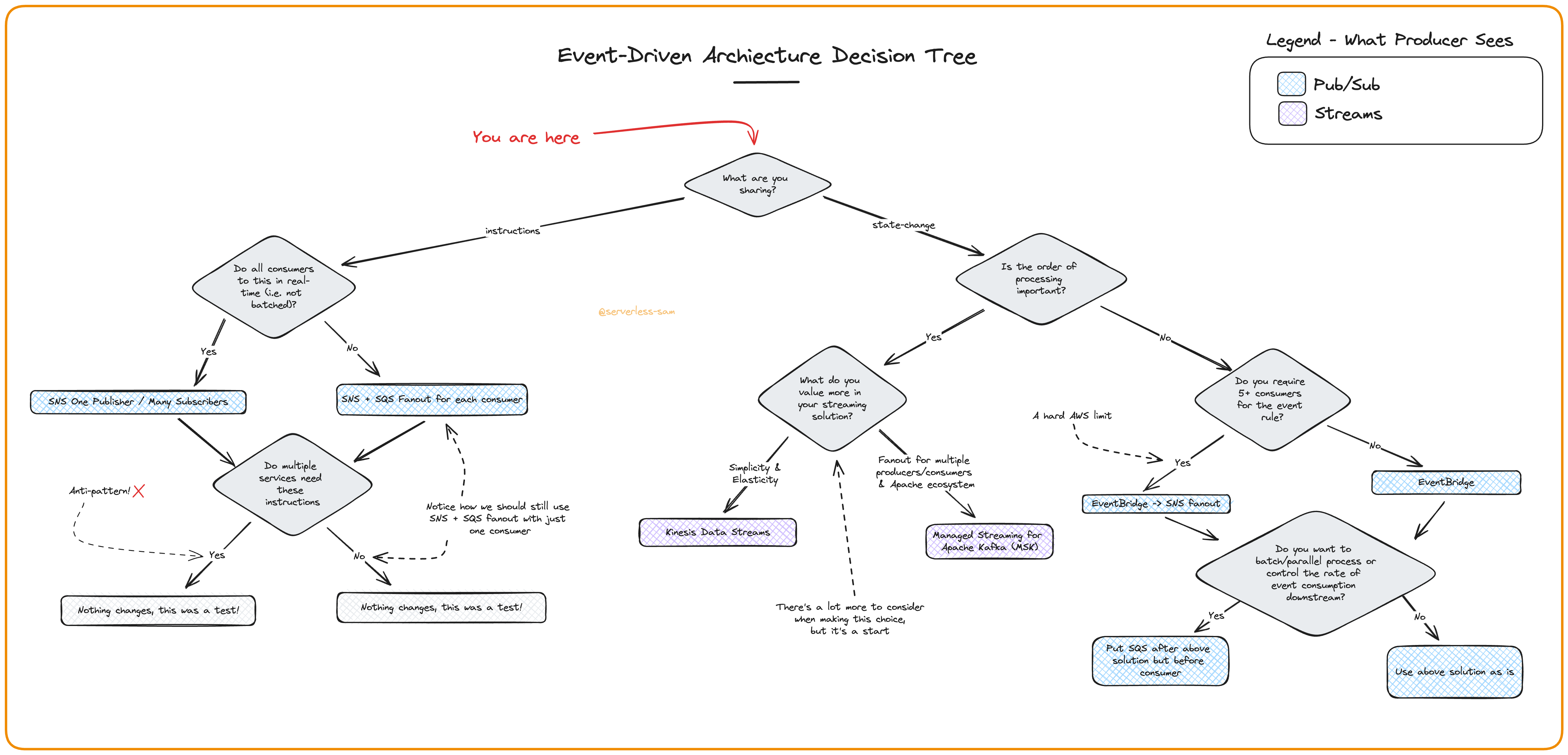
Notice how getting the very first decision wrong sends you on a path of no return. If you command when you should be eventing, you’re gonna have a bad time ⛷️.
Future-Proof your SQS Queues
Back in Part 2, it was mentioned that queues should only have one service consuming from it. Multiple consuming services will be fighting over messages and interfering with each-other.
The solution is to have a queue per consumer.
If you build v1 of your application with service A directly writing messages to a queue consumed by service B - there is no harm done, right?
Now what happens when service C suddenly wants to consume those messages from service A too?:
- Create a new SQS queue for service C.
- Update service A’s code to also write the same message to this new queue.
This also poses a challenge. What if the message is written to service B’s queue successfully but fails to be written to service C’s? If they are delivery (B) and inventory (C) services, a failure to publish a message to service C will result in a delivery being made but stock lists not being updated.
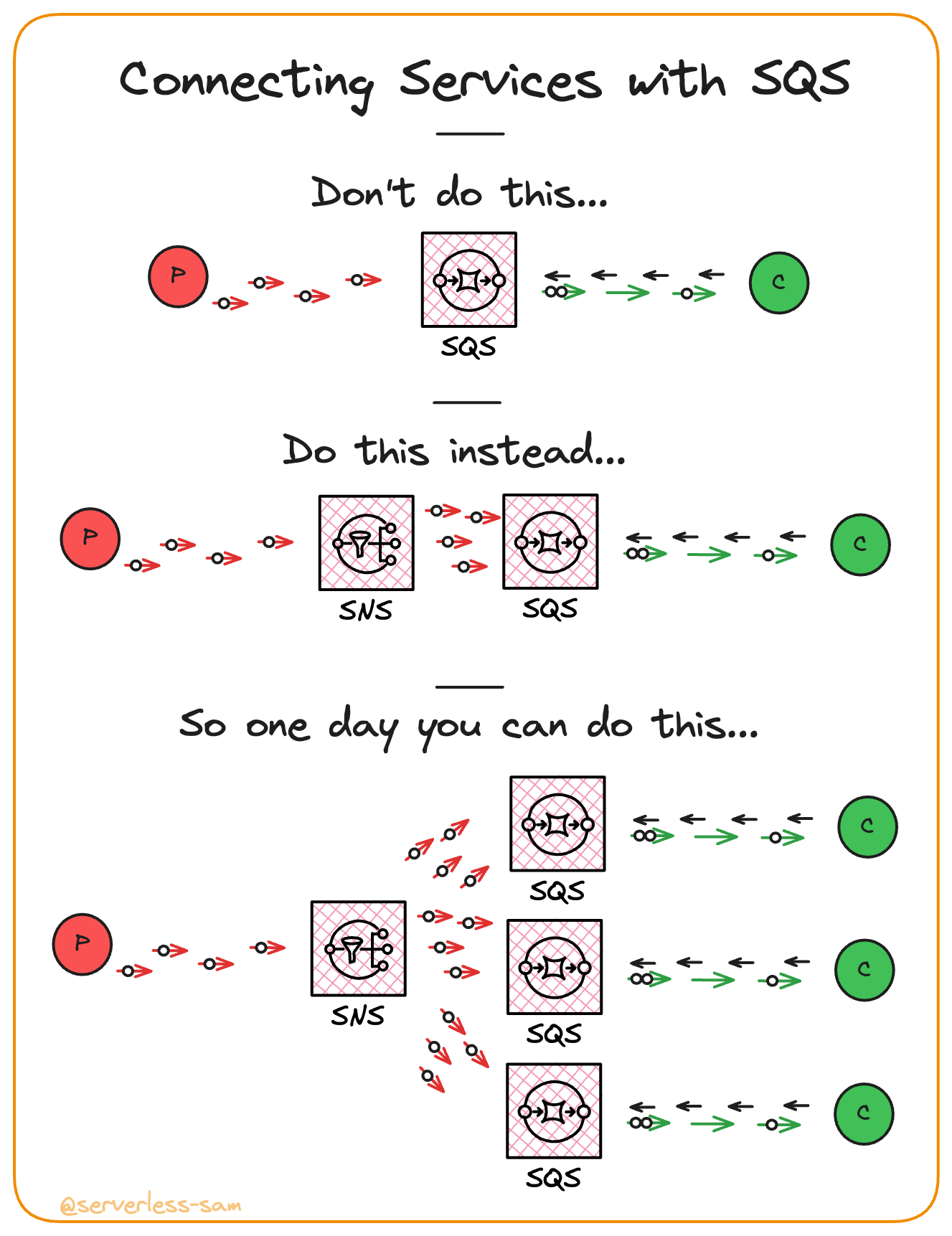
By publishing a message to an SNS topic in service A instead, there are no code changes required in service A when service C wants to consume these messages:
- Create a new SQS queue for service C.
Update service A’s code to also write the same message to this new queue.
Idempotent Streaming with Error Handling
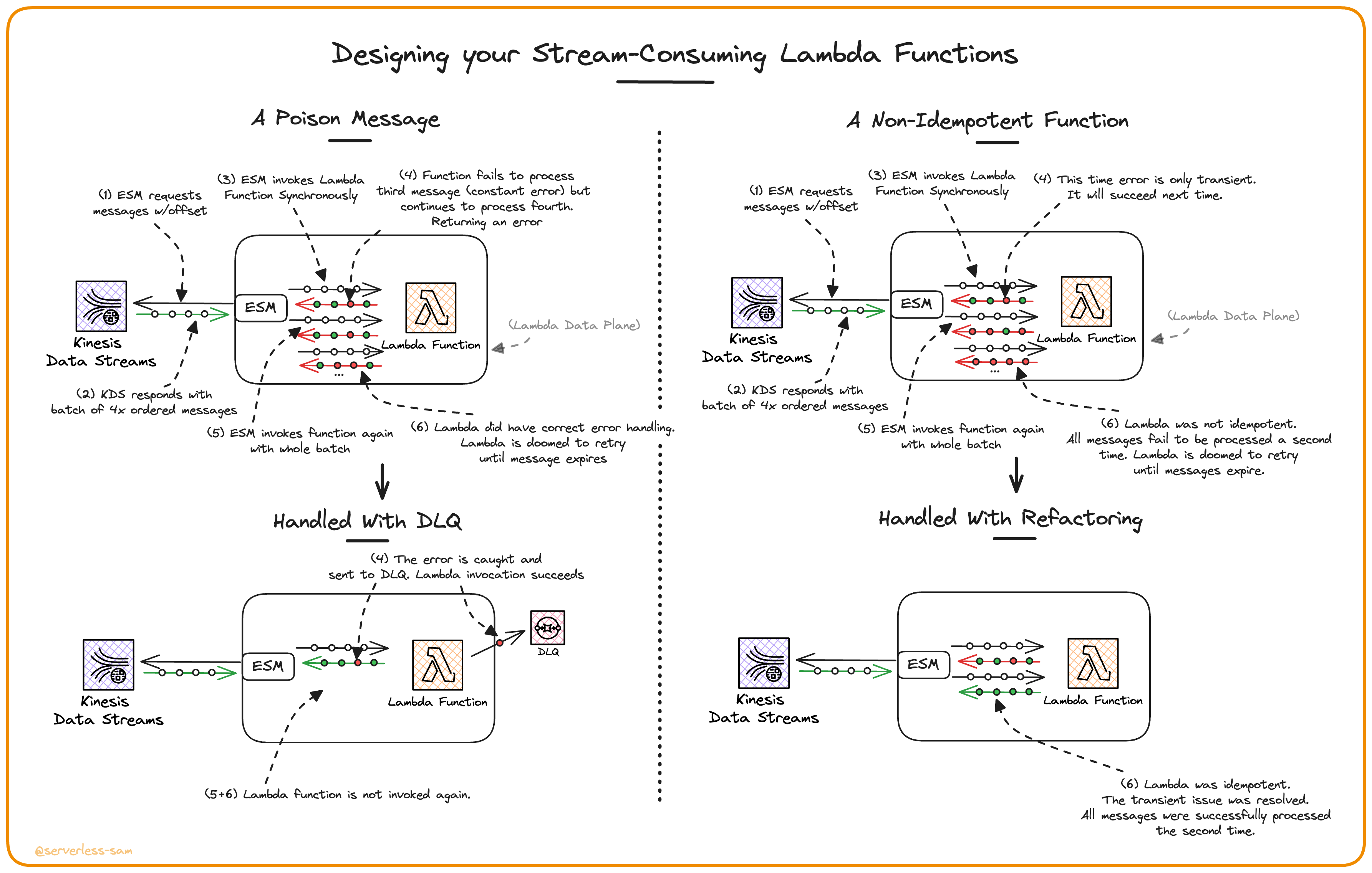
The behaviour of streams can be a blessing but also a curse. It allows you to guarantee in-order processing of all streamed messages - a very powerful assumption to make when writing code.
However, what happens when one of those streamed messages goes wrong? Either:
- A transient error occurs - retrying the message will resolve the issue.
- A constant error occurs - this is a poison message.
Transient Errors
When it comes to transient errors, the solution is to ensure your consumers are idempotent. Even the Kinesis Data Streams documentation agrees:
 There are few scenarios where idempotency is not possible, so just make your processing idempotent, please.
There are few scenarios where idempotency is not possible, so just make your processing idempotent, please.
Constant Errors
Streaming (vs. eventing) means that the consumer should be aware of the context of each message. It should know the order, it should know what message came before it and it will know what message comes after it (…eventually).
This ideology breaks down when there are poison messages in your stream. There are two routes you can take to handle these messages:
- Keep retrying and hold up processing the stream: This is mostly likely applicable to solutions that simply cannot fail. Maybe this is a stream of financial transactions, and the issue must be resolved before the service can continue to consume future streamed messages. But this is a rare requirement that we tend to force upon ourselves with bad application design. The second option is more than feasible in most scenarios.
- Catch the constant error, send to DLQ, and then continue: For most use cases, it’s best if the application continues to process data if a single message is causing failures. Imagine if a video streaming service came to a halt because of a single corrupt frame that could not be processed by clients around the world.
What is important about point 2 when working with Lambda Functions is that you have to provide a false positive back to the event-source mapping. I.E. you have to catch the exception, write it to a DLQ yourself (Lambda Destinations are only supported in asynchronous invocations), and then return a success message from your function.
Conclusion
To conclude this 5 Part article series: Doing event-driven architecture right requires knowledge of the fundamentals. Before jumping into AWS offerings and what they can do, ensure your messaging is correct (command vs. event), ask yourself what behaviour you need from your decoupling mechanism (retries, real-time, eventing vs. streaming), and then you are ready to make a choice of product.
Interested In More?
Connect with me on LinkedIn, Twitter and you are welcome to join the #BelieveInServerless Discord Community.
See you next time!