
For those not reading these articles in series, Part 2 and Part 3 covered queues and event buses respectively. We defined what they fundamentally are, how they are implemented in AWS, and when you should (and should not) use each pattern.
In this article, we will set off downstream and cover the message streaming pattern - so you are never left up the creek without a paddle 🛶
Streaming
Before we introduce streams themselves, let’s start with the action they enable our applications to do - message streaming.
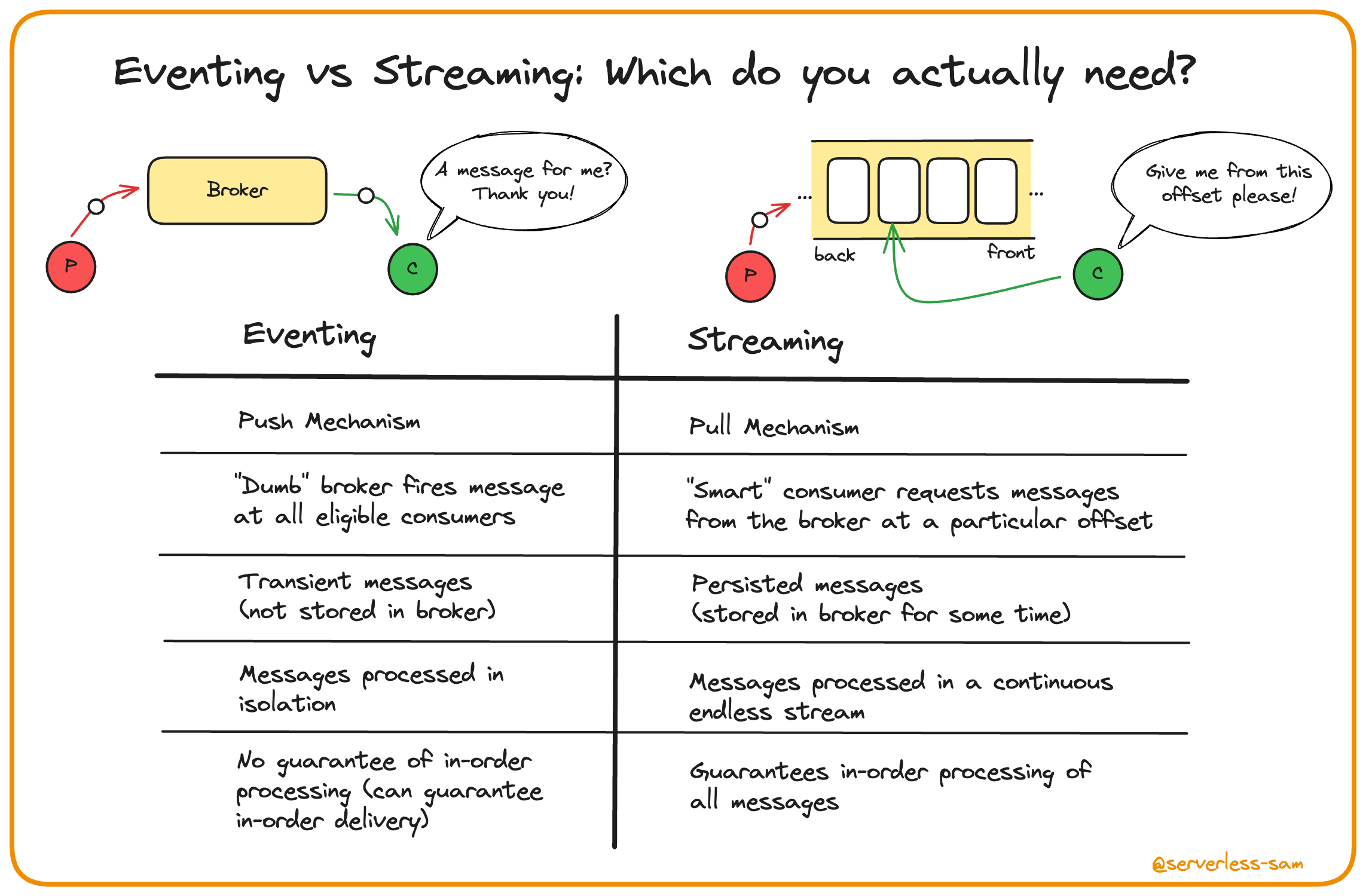
The previously covered pattern, pub/sub, uses what we call eventing. This action is defined as processing each message in isolation. The consumer of the message is simply presented with a message that it needs to process. It does not know what came before, it does not know what comes after. If processing fails, you can implement retry and DLQ logic within the consumer. But this will not prevent new messages from arriving at the interface, being pushed to the consumer and being processed. And this shouldn’t be a problem in eventing because each message is processed in isolation.
If this behavior is a problem for you, then perhaps you should be streaming instead.
Streaming instead requires the consumer to define an offset when retrieving one or more messages from the message broker, i.e a pointer in this continuous flow of messages indicating the desired starting point. This allows consumers to carry out ordered processing. When a particular message is causing failures, the consumer will not skip over it and continue down the stream (unless intentionally programmed to do so).
Streams
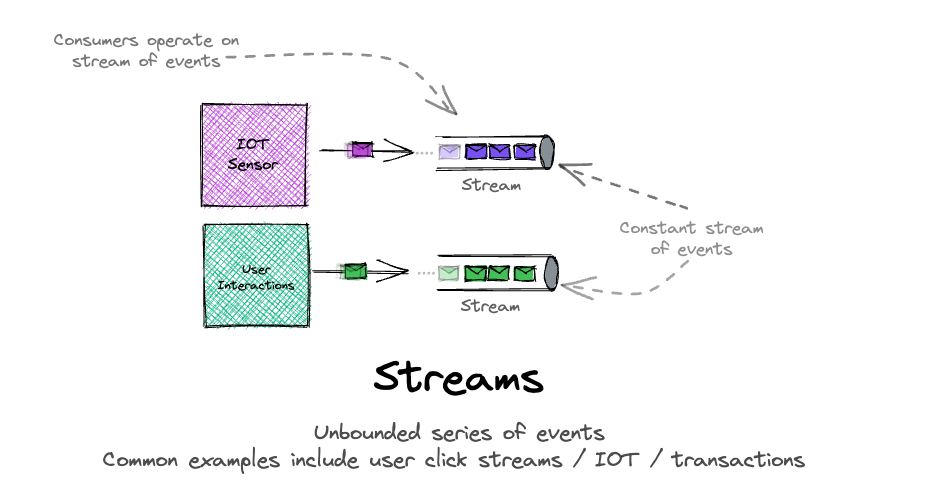
Now that we have defined streaming, let’s theorize what a stream needs to be:
- A broker that persists its messages.
- Each message is given an immutable, ordered ID.
- The interface with consumers must allow the consumer to request messages from a particular ordered ID onwards - or offset.
Credit to @boyney123 - Check him out on ServerlessLand
AWS offers two products that tick all these boxes. Kinesis Data Streams and Managed Streaming for Apache Kafka (MSK).
Kinesis Data Streams
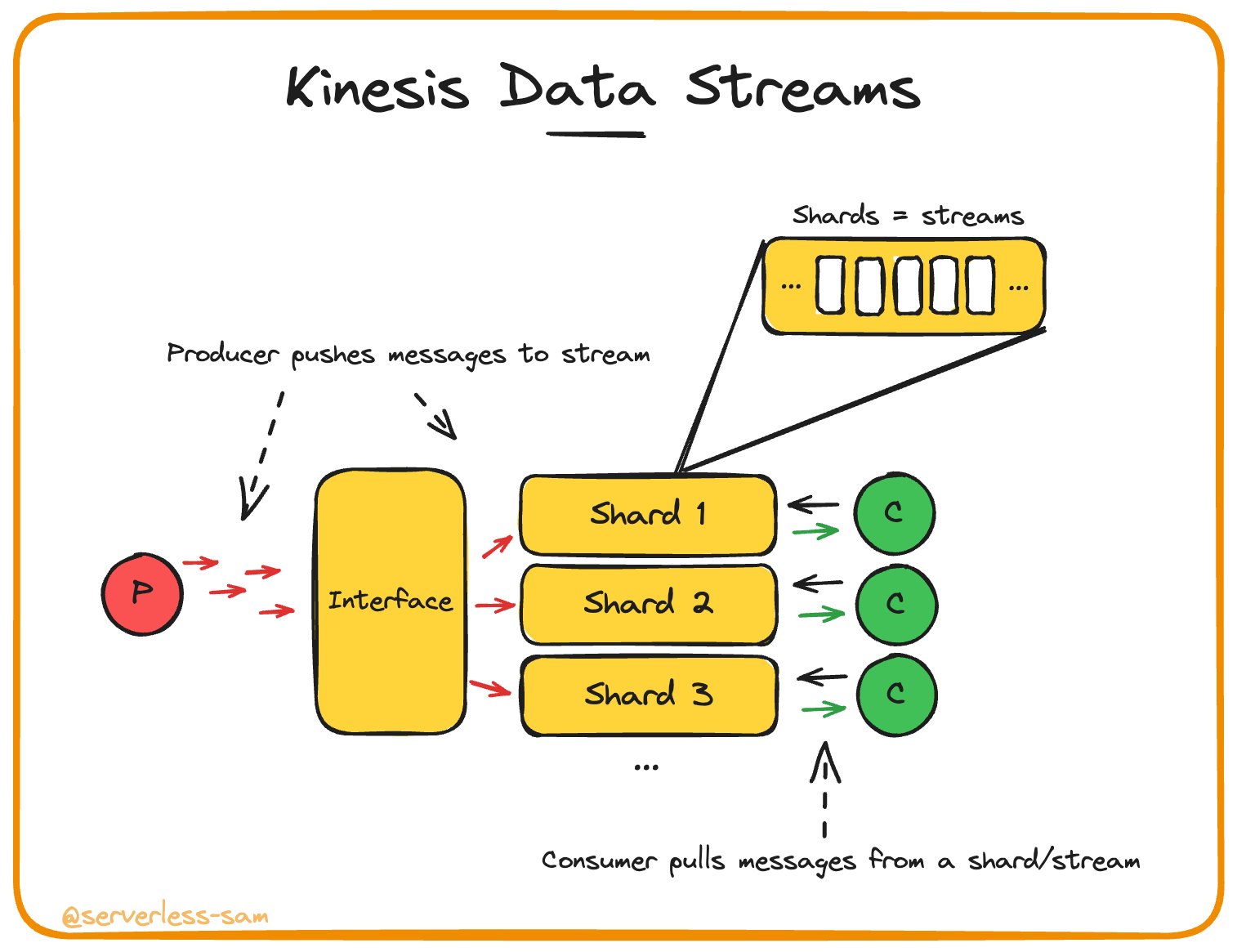
Kinesis Data Streams is considered the simpler implementation of streaming. It hits closer to home when comparing these services to the textbook definition of streaming. It’s key piece of behaviour to focus on is its sharding model.
The producer pushes messages to Kinesis Data Streams with a configured partition key. This key is md5 hashed and converted into an integer, indicating which shard to send the message to. This ensures all messages for a particular partition key value are located on the same shard, guaranteeing correct-order processing if your consumer is pulling from that shard.
Does it meet our streaming litmus test?:
- A broker that persists its messages: Each shard persists messages for a configurable period of 1 day to 1 year. The consumers do not delete messages from their shard after consumption.
- Each message is given an immutable, ordered ID: Each message is given a sequence number specific to its value of the partition key (i.e. all messages for a given partition key value will have incrementing sequence numbers).
- The interface with consumers must allow the consumer to request messages from a particular ordered ID onwards - or offset.: This is exactly how consumers read from shards - see the GetRecords request.
Managed Streaming for Apache Kafka (MSK)
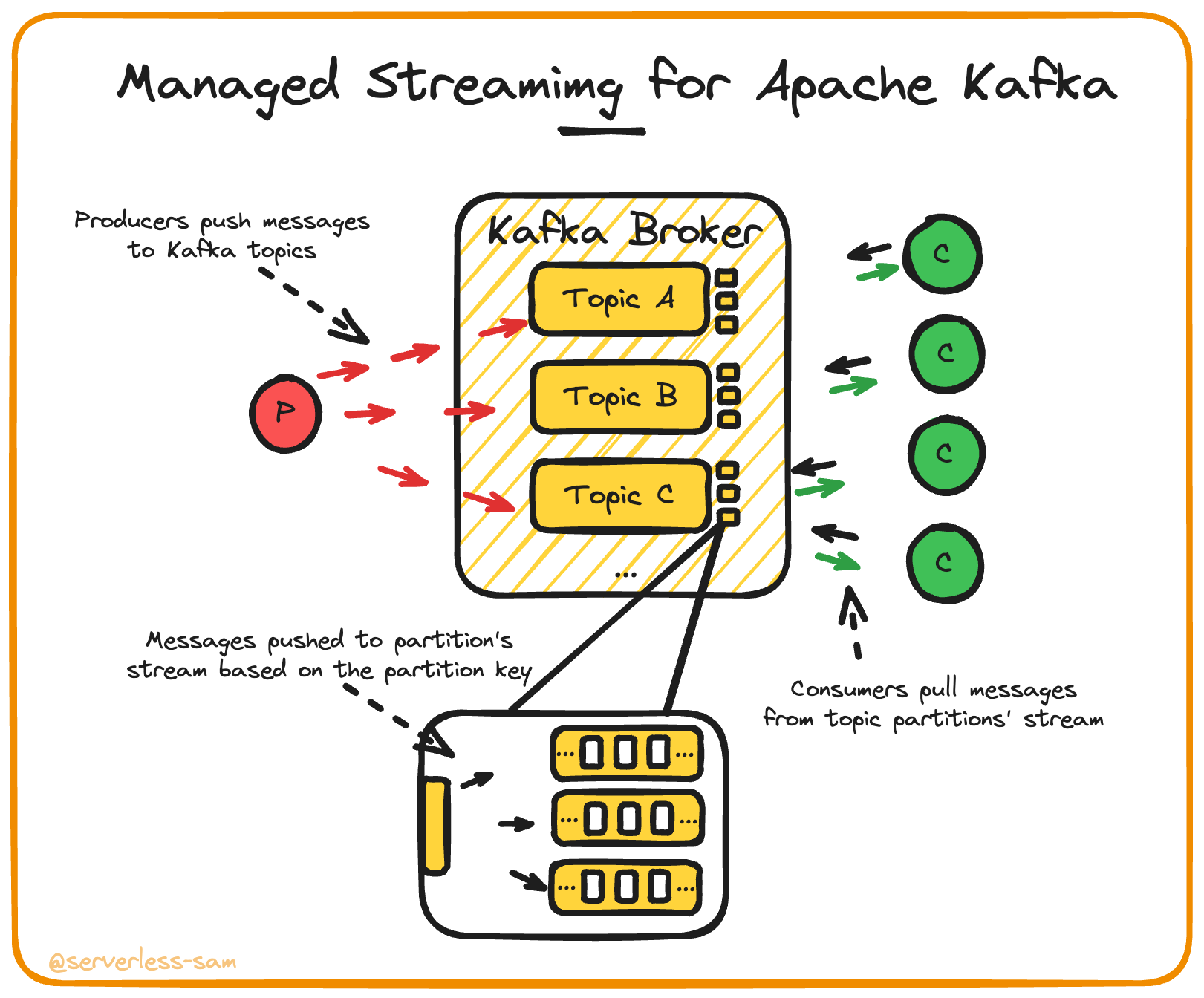
MSK is a hosted offering of the open-source Apache Kafka platform. The management of the Kafka cluster is abstracted away from you (it uses EC2 🤢).
It differs from Kinesis Data Streams in the fact that it also implements a layer of pub/sub on top of it’s streams. Kafka has topics, allowing producers of different events to push messages to different topics. This allows consumers that are only concerned with one type of event to consume only from that producer’s topic.
Once the pub/sub logic is sorted, the consumers are essentially pulling messages from a stream. Partitions are implemented in Kafka in the same way mentioned for Kinesis Data Streams (keying off the partition key).
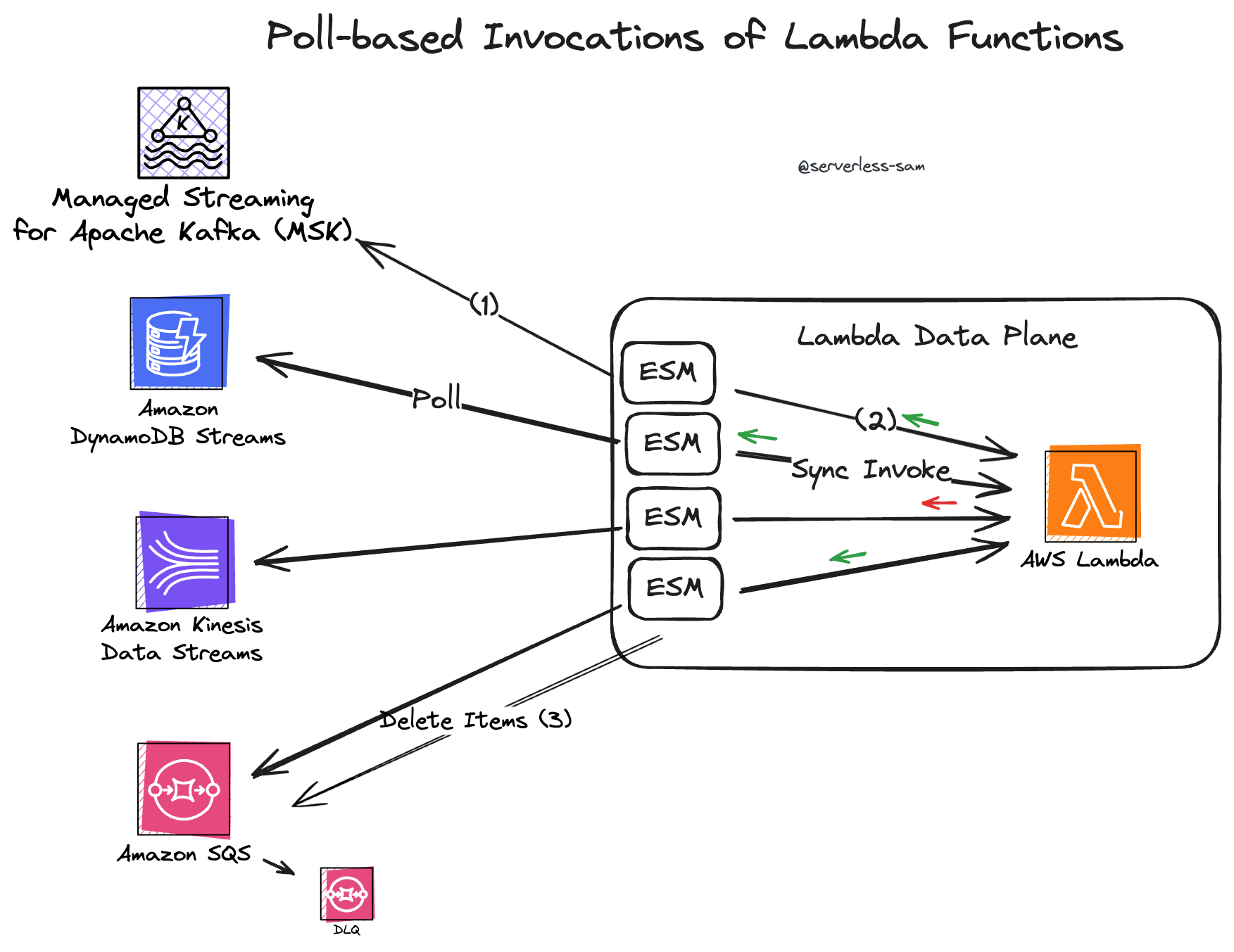
Lambda Poll-Based Invocations
The first diagram of this article made consuming from streams quite simple:
- Pull messages by providing an offset.
- When ready for more messages, pull more messages providing the new offset.
- Repeat indefinitely.
However, this approach does not scale well. Streams persist their data, they are designed for high-volume event writes, and your consumer may only want to process a subset of stream messages.
Partioning was introduced in both of the AWS offerings above, which helps scale these services. But how do you ensure messages are processed exactly once, in order, across all of these partitions in a serverless environment? Lambda Functions are small stateless ephemeral environments that are not aware of each other. How do you coordinate this processing?:
- Ensure only one Lambda Function is processing each partition (from each topic, if applicable) at any one time.
- This means we need to synchronously invoke each Lambda Function.
- When a stream message fails to be processed, the coordination must ensure that the event is retried (until expiration!).
And that is exactly how the Kinesis Data Streams and MSK event-source mappings for Lambda work.
When to Use Streams
Common examples of using streams will usually involve ingesting a large-scale dataset, such as IOT or clickstream events. While it is true that streams are a good choice (due to the large volume of data these scenarios tend to produce), there are plenty of other use cases that may go unnoticed.
Video Streaming
Yes, if asked whether you are receiving your Netflix show via eventing or streaming, I expect a unaminous “streaming, duh” answer. But let’s dissect why. Over the years, we saw the number of “p” ’s rise on our videos. From 350 to 720 to 1080. Now we expect to see 4K. Internet download speeds haven’t improved that drastically to support this, so how is it possible that we are not constantly buffering?
The answer is improved compression and encoding methods. One of which, is delta encoding
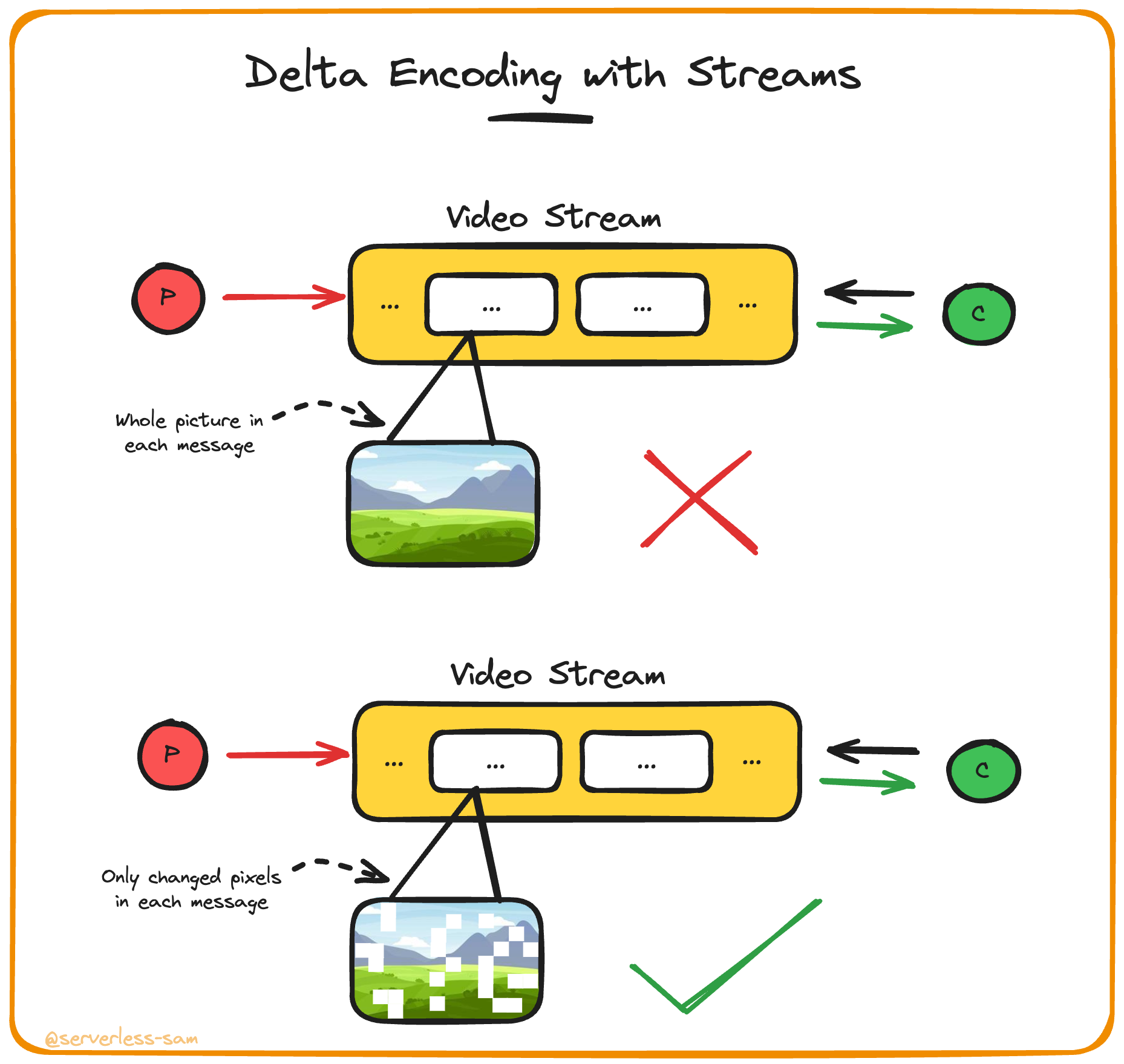
Delta encoding involves only sending a message containing what has changed from the last message sent - rather than the whole updated state. In the case of video streaming, this involves only sending the pixels that change.
Ever notice when watching a football match that you tend to see buffering when camera angles drastically change? When most pixels are green and stay green, there is very little delta. Therefore, a smaller event is being sent-to and retrieved-from the stream. When the camera angle changes, there is a spike in the number of pixels changing colour.
How is delta encoding possible?
Because streaming events can guarantee the in-order processing of events. So your architecture can assume that the consumer always has the previous state of all pixels.
Evolving State
It is common for applications to be responsible for reacting to changes in the state of a particular resource. For example, when user data changes. When everything is kept in native AWS services this is easy. If your users are stored in DynamoDB, you can leverage DynamoDB streams (another stream!) to react to object INSERT, UPDATE or DELETE operations.
But what if your users are stored with a 3rd party vendor?
Here are three approaches to propagating these changes to a downstream service:
- ❌ When user configuration changes, push a message to a queue (for each consumer). The message needs to contain the whole configuration of the user, because queues will not guarantee in-order processing (message will move to DLQ after too many failures).
- ❌ The producer should determine what has changed and emit a specific event for just that, e.g.
FirstNameChanged,EmailChanged,SalutationChanged,MarketingOptOutto an event bus. This obviously does not scale well. Consumers require the producer to implement the logic to detect the specific event they are interested in, and this introduces tight coupling and complexity in the producer. - ✅ The producer simply writes a message to a stream, detailing what changed between the current configuration and the previous version. This allows the consumers of the stream to filter and react to whatever configuration changes they are interested in. Streams allow you to implement delta encoding - which can greatly reduce complexity, coupling and data transfer costs.
Tomorrow: Part 5
Making informed decisions in event-driven architecture is hard.
The article series so far has helped inform readers. Now we need to focus on the decisions.
In the final article of this Level Up: Event-Driven Architecture series, we will cover common patterns that use queues, pub/sub and streams together to process messages of varying requirements.
Interested In More?
Connect with me on LinkedIn, Twitter and you are welcome to join the #BelieveInServerless Discord Community.
See you tomorrow!