
In yesterday’s Part 1 article we defined what commands and events are. It was explained that events are state-changes that are broadcast to multiple subscribers, and the producer is not aware of them. However, the producer of commands is aware of it’s one consumer.
Today we will begin putting these concepts into practice and cover the concept of queues: what are they good for and when to use them.
Queues
A queue is simply a collection of messages.
A producer writes messages to the back of the queue, and a consumer reads from the front. It is worth noting that the textbook definition of queues is that they are “dumb”, i.e. there is no built-in state management of messages. They simply store messages in an order. When a consumer is finished with a message at the front of the queue, it is their responsibility to delete that message from the queue.
If you want multiple services to read from the queue, they will have a hard time sharing messages. As stated above, consumers simply read from the front.
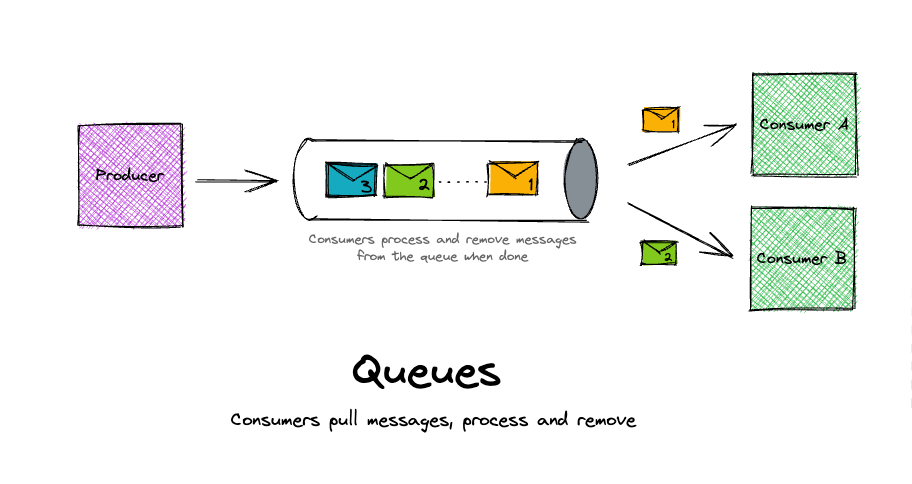
Notice how in the image above (credit to @boyney123 - Check him out on ServerlessLand), Consumer A and Consumer B are both green. This is because they are both instances of the same service - they both do the same thing with messages. If they were different services, service A and B would only be fetching message #1 and #2 respectively. This alternating pattern would repeat, with each service only being aware of 50% of the total messages.
Not great if these were payment and inventory services for an e-commerce website! Half of customers would receive their item and half would actually pay for it!
However, since Consumer A and B are from the same service (above), it allows the consuming service to horizontally scale and process more messages per second. And this is a great reason to use queues.
Now ask yourself: if one of these consumers were to fail the processing of their message, what would happen?
If the producer were to avoid queues and simply invoke the consumer via some kind of load-balanced asynchronous API, each consumer would need to properly handle failures and retry. And what happens if that doesn’t work? Maybe the consumer was passed a poison message that is doomed to fail every time. Will that consumer retry the message until the end of time?
This is where the “dumb” nature of queues comes to the rescue. It is the responsibility of the consumer to read from the front of the queue and then delete the message once processing is complete. If a consumer fails to process a message, it can simply fail and leave the message in the queue to be tried again. But will that not leave the poison message at the front of the queue until the end of time?
SQS
SQS wraps a few mechanics around the core principle of queues to combat poison messages:
- Message Visibility Timeout: When a message is retrieved by a consumer, SQS sets that message (which is still in the queue) to be invisible to all other consumers for a specified period of time.
- “Maximum Receive Count” property: This configurable property tells SQS how many times a message can be set invisible, then made visible again. When the visability timeout is exceeded, this is an indicator that the Lambda Function acting as the consumer failed to process the message. And when this counter is exceeded, the message is doomed.
- DLQs: SQS can assign another queue to be its dead-letter queue. This is a graveyard for failed messages. If configured for an SQS queue, SQS will move a failed message from it’s main queue to the DLQ when the Maximum Receive Count is exceeded.
Let’s not forget to give a shoutout to the Lambda Event-Source Mapping which is the other half of the brains in this solution.
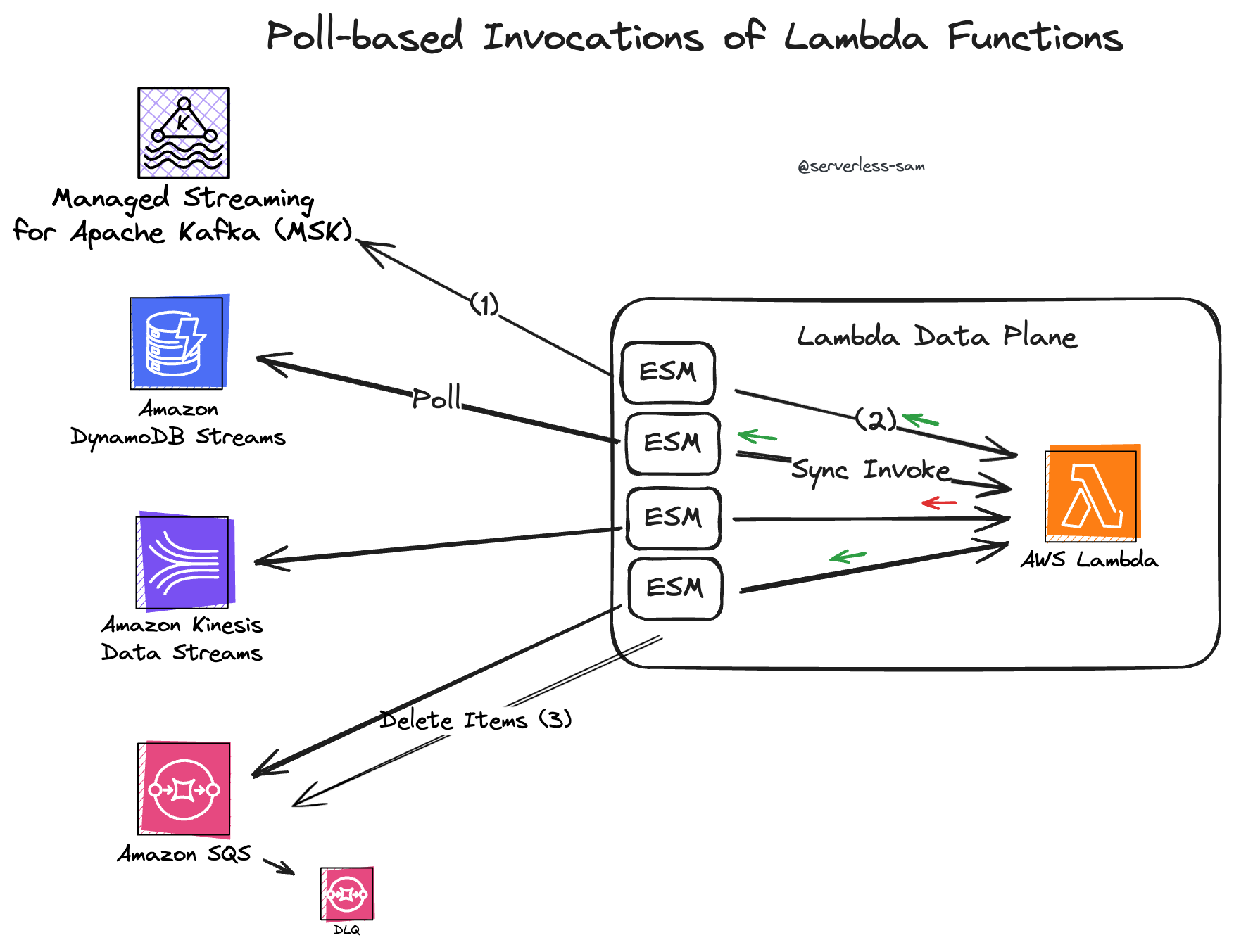
The ESM is interacting with SQS via the AWS API just like us! There is no magic happening here. The Lambda ESM is doing the following:
ReceiveMessageBatch: Receiving batches of messages from the SQS queue. Remember, every message returned will become invisible to all other consumers for the defined message visability timeout.- Making a synchronous invocation of our Lambda Function.
DeleteMessageBatch: Deleting messages if the whole batch is processed successfully.
The ESM simply relies on SQS to set messages to the visible/invisable state. This is why it is important that your message visability timeout doesn’t exceed your Lambda timeout - otherwise your messages can be processed multiple times.
When To Use Queues
The first decision to make is whether messages processed through queues should be commands or events
The answer is that either can work, but they are better suited to commands.
Commands (usually) need guaranteed processing - something that queues offer due to their retry and DLQ behavior. Commands are also targeted towards their consumer. Since queues should only have a single consumer service, this also fits the requirements.
Events are less of a perfect fit for queues. This is because events are intended to be broadcast to multiple subscribers, and their payload should be considered a non-targeted state-change. You would struggle to get multiple services to receive the same event through a queue.
However, queues can be useful tools when processing events:
- If event traffic is spikey and does not need to be processed in real-time: Putting a queue between the subscriber’s entry point and the processing compute can allow horizontal scaling to handle spikes in events.
- If guaranteed delivery is required: The same argument was made for commands, if you need assurances that an event is processed, it is best to front the processing compute with a queue.
Notice how in both points I mention that we front the consumer’s compute only. You should still use something event-friendly as the entry point into your downstream service.
Other Usecases
Queues are also a useful tool when attempting to write idempotent code.
Let’s say you are building a service that takes a payment from a user and then sends them an email confirmation. If your email flow were to fail (maybe they gave a non-conforming email address and all attempted emails bounce), what do you do?
If you rerun the whole execution again, you will take a second payment from that user.
A queue could be placed between the code that takes the payment and the code that sends the email confirmation. That way, if the email portion of your solution fails, there will be a command to send an email that remains in your queue. A retry will simply try to send the email confirmation only.
🎉 Idempotency achieved! 🎉
Tomorrow: Part 3
Tomorrow, part 3 of this Level Up: Event-Driven Architecture series will take you on a bus ride you won’t forget!
🚌 An event bus ride that is 🚌
Interested In More?
Connect with me on LinkedIn, Twitter and you are welcome to join the #BelieveInServerless Discord Community.
See you tomorrow!