
April fools is an opportunity to be creative. And any opportunity to be creative leads to innovation.
This was why I set out to do something never done before. I wanted to power an API using entirely AWS CloudFormation. That means no compute - I.E. no EC2, containers or Lambda Functions. Why did I decide to spend my long bank holiday weekend doing this? Not because it should be done, but because it can be done.
I call this: Code-As-Infrastructure (not be confused with the popular cloud deployment approach: “Infrastructure-As-Code”).
The Objective
The goal was to create a simple CRUD API. The API should avoid using any deployed compute and storage resources. The resulting API can be found here (used as the game’s leaderboard in the top right of the screen).
A breakdown of the project can be found in a video posted to LinkedIn. (I also want to take the opportunity to share the Tetris frontend which I forked from a public GitHub repo - in case you wanted to try this at home).
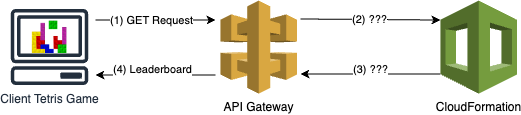
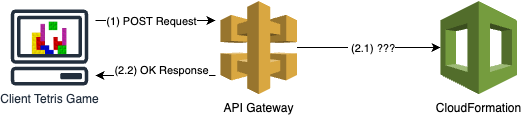
I planned to create a “read” (GET) API route and a “write” (POST) API route. The “read” route would retrieve the current leaderboard state, and the “write” route would append the provided score into the leaderboard asynchronously (I’m doing this in a weekend, I did not need a “write” response).
Storing Leaderboard Data
The leaderboard must persist data somewhere, and read it during a future invocation. Naturally you would think that a database solution would be required. Perhaps RDS, DynamoDB or even S3.
The issues with these solutions is that none of these three expose their stored values as CloudFormation resource attributes. So I would not be able to read the current leaderboard value, then append it. An early stumbling block, however I had planned for this.
I had two options:
First Storage Option (SSM Parameter Store)
After doing some digging (thank you Yan Cui’s CloudFormation Cheat Sheet) I found a potential solution - SSM Parameter Store!
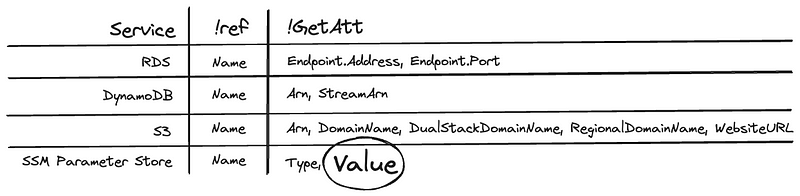
In fact, this alternative was superior to my initial three options, because it’s free* and scales with no charges incurred!
*Assuming a “Standard” type parameter and “Standard Throughput” is used. Which is fine for this use case.
The Problem
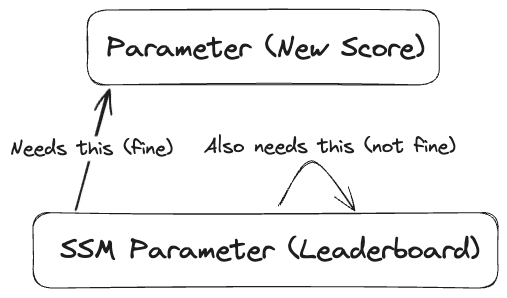
In order to add a new score to the leaderboard, the template would need to set the SSM parameter’s value to: !GetAtt <my_parameter_logic_name>.value appended with the template parameter’s new score.
Because our SSM parameter is referencing itself, a circular dependency is created which CloudFormation cannot resolve.
Second Storage Option (CloudFormation Outputs)
The alternative was to leverage the CloudFormation stack output as a data storage solution. This allows me to:
- Write to my storage during a CloudFormation stack create/update via the
Outputskey of the template file. - Read from my storage within my template during a stack create/update via
!ImportValue <exported_outputs_name>. - Read from my storage via the outputs key in the response of an DescribeStacks AWS operation.
So I am able to read from/write to my storage during a POST API call, and I am able to read from my storage during a GET API call.
The Problem
Because CloudFormation outputs are not resources, updating a stack with just a new parameter (new score) does not change any resources. So the template update is cancelled.
The Solution
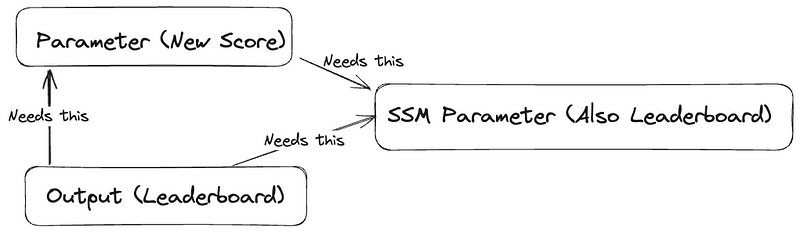
In order to tell CloudFormation to update my stack, what I needed was to use an intermediary. Something I could assign the current value of my leaderboard to during stack updates, then reference in my output.
Something like … a runtime variable.
Implementing Runtime Variables
So it turns out the solution was in fact right under my nose the whole time. I already had two methods of reading/persisting a string.
The solution was to use the SSM Parameter as a runtime variable and CloudFormation output as the storage. Now I can also access the current value of my leaderboard using the following CloudFormation:
|
|
And we establish the following pattern:
API Gateway Integration
Hurrah! It works!
The CloudFormation template was successfully appending new scores to my leaderboard value, which I could access via the CloudFormation stack output (also technically the SSM parameter directly!).
In order to achieve my goal of providing this API with no code, I leveraged the direct integration between API Gateway and AWS services. The VTL for the GET request was relatively simple. I just hardcoded the stack-name in VTL and passed that along to the DescribeStacks CloudFormation action.
For the POST request, I actually wanted to create a generic VTL which could dynamically set multiple parameters (I wasn’t sure if I would need more by the end of the weekend). I achieved this using the following VTL snippet:
|
|
In hindsight, I could have just passed the $parameters string straight through to the Parameters variable in the UpdateStack request. I think the weekend of meme-driven architecture was taking it’s toll.
However I wanted to share this VTL pattern as I found the documentation quite light, and this was my first experience with VTL. I now see why all the AppSync-ers rejoiced when JS resolvers were announced for AppSync.
Assessing The Solution
Whilst unorthodox, we should always ask ourselves “why not?” when making technical decisions. The “Code-As-Infrastructure” architecture pattern:
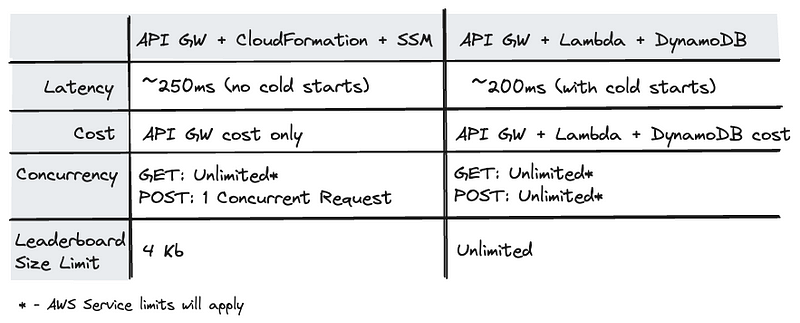
- Removes the problem of cold starts, whilst remaining truely serverless.
- Has zero cost (outside the cost of the API Gateway).
- Has unlimited* concurrency for GET requests.
However it unfortunately has it’s downfalls:
- Only supports one concurrent POST request at a time (due to the CloudFormation stack being in an UPDATE_IN_PROGRESS state for a few seconds upon each leaderboard update).
- The leaderboard is restricted to the size allowed for a single SSM Parameter (4Kb).
Conclusion
Of course, this article is not providing any serious recommendations for creating serverless APIs. However exercises like this give you the opportunity to discover what AWS services are actually capable of. I personally got to:
- Write a API Gateway VTL resolver for the first (and hopefully last) time.
- Use ChatGPT to help integrate this API into the Tetris frontend (I am a backend developer).
- Use the AWS Application Composer to put together the template.
So whilst this (and any other patterns of Meme-Driven Architecture) may not have any real-world applications, they are a great learning experience!
Do you have an idea of what I can try next? Or have some Meme-Driven Architecture ideas of you own? Reach out to me on Twitter/X and LinkedIn.